
예상독자
- 배열 구조의 앱로그 데이터를 다루고 싶은 사람
- BigQuery 함수 기반으로 앱로그 데이터를 전처리 방법을 알고 싶은 사람
- 데이터분석의 전반적인 프로세스를 알고 싶은 사람
- 윈도우 함수를 사용하여 데이터집계 쿼리를 작성하고 싶은 사람
글을 쓰게 된 배경과 목적
이번글은 우선 강의를 들은 내용을 한 번 정리하는 시간을 가지고 싶었다.
새로 알게 된 함수위주로 작성하려다가 조금 더 욕심내서 빅쿼리 데이터로 어떻게 데이터분석을 하는지 시각화와 Action item까지 전체적인 프로세스를 정리해 보기로 했다.
글에서 중점적으로 작성할 내용:
- 빅쿼리 환경의 데이터구조 파악하는 방법
- 원하는 형태의 데이터 집계를 위해 어떤 식으로 데이터전처리를 진행하는지
- 빅쿼리 환경에서 사용할 수 있는 함수들의 정의와 용도
- 쿼리를 통해 나온 결과값으로 어떻게 시각화를 해서 데이터를 파악하는지
- 그에 따른 액션 아이템을 어떤 방향성으로 생각하는지에 대한 내용이다.
분석 환경
- 도메인: 배달음식 주문 어플리케이션
- 데이터셋: 어플리케이션의 앱로그 데이터
- 데이터분석 목적: 서비스의 사용자 현황 파악 ▶ 시간대, 일, 요일, 월별 사용자수를 통해 현재 서비스 이용 패턴 확인
목차
1. 데이터 구조 파악
1-1) 스키마 확인
1-2) 데이터 출력 형태 확인
2. 데이터 전처리
2-1) 사용함수 정의 및 목적
2-2) 결과 쿼리
3. 데이터분석
3-1) 데이터 집계 쿼리 작성
3-2) 시각화 및 Action item
4. 마무리
1. 데이터 구조 파악
데이터 구조 파악은 분석의 첫 번째 단계로, 데이터의 특성과 가능한 분석 방향을 결정하는 과정이다.
이 단계에서는 다음과 같은 요소들을 검토한다.
- 데이터 크기 및 유형(구조) 확인
- 컬럼 구성 및 데이터 타입 확인
- 결측치, 이상치 등 정확성 확인
예를 들면,
timestamp가 초단위까지 있는지, 특정형식으로 변환되어 있는지,
데이터가 배열로 되어있는지, 중복값이 있는지, 데이터 타입을 변경할 필요가 있는지 등의 확인이 필요하다.
봐야 하는 데이터가 무엇인가, 집계를 어떤 방식으로 할 것인가 대략적으로 파악하는 단계다.
1-1. 스키마 확인

데이터 구조 특징
event_params의 데이터가 key-value 쌍으로 구성된 배열 형태.
하나의 이벤트에 대해 여러 개의 파라미터가 존재
기본 식별 컬럼
- user_id: 숫자형(INTEGER), 사용자 고유 식별자(예: 54945, 28151)
- user_pseudo_id: 문자열(STRING), 사용자 ID (예: 1836819819.8030003519)
- platform: 문자열(STRING), 사용자 접속 플랫폼 정보 (예: iOS)
이벤트 관련 컬럼
- event_name: 문자열(STRING), 이벤트 유형 (예: click_cart, click_payment)
- event_date: 날짜형(DATE), YYYY-MM-DD 형식 (예: 2022-08-03)
- event_timestamp: 숫자형(INTEGER), 마이크로초 단위의 타임스탬프 (예: 16608494...)
이벤트 파라미터 컬럼
- event_params_key (param_key): 문자열(STRING)
- firebase_screen
- food_id
- session_id
- event_params_value_string_value (string_value): 문자열(STRING)
- food_detail
- 세션 ID 값 (예: 740746b8-89b8-43ba-b58e-44...)
- event_params_value_int_value (int_value): 숫자형(INTEGER)
- food_id 값 (예: 1144, 1519)
1-2. 데이터 출력 형태 확인
아래의 이미지를 보면 배열구조의 형태를 좀 더 이해할 수 있다.
event_params의 데이터가 다음과 같은 특징을 보인다.
하나의 이벤트에 대해 여러 개의 key-value 쌍이 존재하며 각 key-value 쌍이 반복되는 구조이다.
동일한 event_timestamp에 대해 여러 행으로 표시된다.
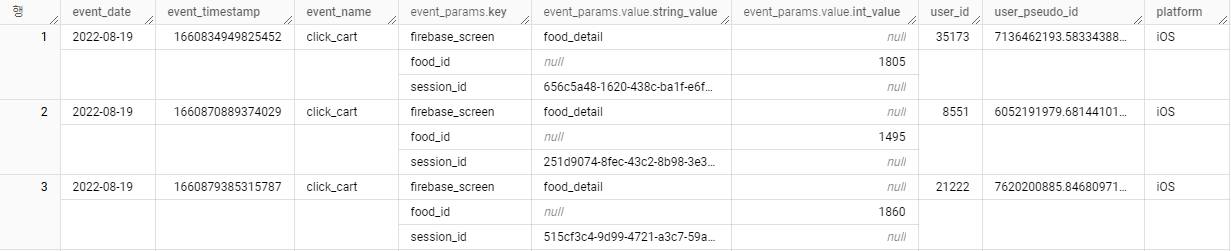
이러한 구조는 ARRAY<STRUCT> 타입의 특징을 보여주며,
Firebase Analytics나 Google Analytics의 일반적인 데이터 구조이다.
2. 데이터 전처리
2-1. 사용함수 정의 및 목적
① 임시 테이블 정의 (WITH)
WITH 사용 시 임시 테이블을 생성하여 쿼리 내에서 재사용할 수 있다.
복잡한 로그 데이터 처리 시, 쿼리를 가독성 좋고 관리하기 쉽게 만들기 위한 함수다.
② 중복제거 (DISTINCT)
사용자가 같은 행동을 여러 번 시도하거나 데이터 오류로 중복 이벤트가 발생할 수 있다.
현재는 고객수의 유니크값을 얻기 위해 조회하는 컬럼을 조합해서 중복된 값이 있으면 제거한다.
③ 시간형식변경 (TIMESTAMP)
- event_timestamp는 마이크로초 단위의 Unix timestamp 형식이다.
- TIMESTAMP_MICROS: 마이크로초 timestamp를 datetime으로 변환
- 'Asia/Seoul' 타임존 적용으로 한국 시간 기준 분석이 적절하도록 변환한다.
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul')
④ 배열구조 →개별 행 변환
데이터 중 event_params가 배열이기 때문에 개별 행으로 분리해야 파라미터에 접근이 가능하다.
배열구조를 행으로 분리하는 unnest 함수로 진행한다. (event_params를 개별 행으로 변환)
CROSS JOIN UNNEST
- ARRAY를 행으로 변환하는 BigQuery의 함수
- CROSS JOIN과 함께 사용하여 원본 테이블의 각 행과 배열의 요소를 결합
- 결과적으로 배열의 각 요소가 개별 행으로 확장
CROSS JOIN UNNEST(event_params) as event_params
2-2. 결과쿼리 (base)
WITH base AS ( # 2-1 임시 테이블 정의
SELECT
DISTINCT # 2-2 중복제거
user_id,
user_pseudo_id,
event_name,
DATE(DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul')) AS event_date, #2-3 시간변환
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') AS event_datetime,
event_params.key AS param_key,
event_params.value.string_value AS string_value,
event_params.value.int_value AS int_value
FROM advanced.app_logs
CROSS JOIN UNNEST(event_params) as event_params # 2-4 배열구조 처리
WHERE event_date BETWEEN "2022-08-01" AND "2022-12-31"
)
SELECT * FROM base
데이터 결과 예시

3. 데이터 분석
데이터 구조 파악 후 분석하고자 하는 목적에 맞게 필요한 컬럼과 데이터 처리 요구사항이 무엇인지 정의한다.
필요한 데이터를 추출하고 가공하기 위해 쿼리를 작성하여 데이터 집계 결과를 생성하고, 분석에 적합한 형태로 데이터를 변환한다.
3-1. 데이터 집계 쿼리 작성
-- base 쿼리 생략
-- 시간대별 사용현황
WITH hourly_analysis AS (
SELECT
EXTRACT(HOUR FROM event_datetime) as hour,
COUNT(DISTINCT user_id) as users,
COUNT(DISTINCT CASE WHEN event_name = 'click_cart' THEN user_id END) as cart_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) as cart_payment
FROM base
GROUP BY hour
ORDER BY hour
),
-- 일별 사용현황
daily_analysis AS (
SELECT
event_date,
COUNT(DISTINCT CASE WHEN event_name = 'screen_view' THEN user_id END) as view_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_cart' THEN user_id END) as cart_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) as payment_users
FROM user_journey
GROUP BY event_date
),
-- 요일별 사용현황
weekly_analysis AS (
SELECT
FORMAT_DATE('%A', event_date) as weekday,
COUNT(DISTINCT user_id) as users,
COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) as click_payment
FROM base
GROUP BY weekday
ORDER BY CASE weekday
WHEN 'Monday' THEN 1
WHEN 'Tuesday' THEN 2
WHEN 'Wednesday' THEN 3
WHEN 'Thursday' THEN 4
WHEN 'Friday' THEN 5
WHEN 'Saturday' THEN 6
WHEN 'Sunday' THEN 7
END
),
-- 월별 사용현황
monthly_analysis AS (
SELECT
FORMAT_DATE('%Y-%m', event_date) as year_month,
COUNT(DISTINCT user_id) as users,
COUNT(DISTINCT CASE WHEN event_name = 'click_cart' THEN user_id END) as cart_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) as payment_users,
ROUND(COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) * 100.0 /
NULLIF(COUNT(DISTINCT CASE WHEN event_name = 'click_cart' THEN user_id END), 0), 2) as cart_to_payment_rate
FROM base
GROUP BY year_month
ORDER BY year_month
)
3-2. 데이터 시각화 및 Action item
Google Spread Sheets를 통해 BigQuery 데이터를 연결하여 간단하게 차트로 시각화했다.
① 월별 사용자 현황
월별 유저수와 전월 대비 유저수가 얼마나 증가했는지 증감률을 파악하기 위한 차트다.

8월: 6,424명 → 12월: 20,156명 (3배 성장)
9-10월: 가장 급격한 성장세
10월 이후: 안정적 MAU(Monthly Active User) 유지
→ 9-10월 70%대의 사용량의 성장세를 보이다가 11월에 감소 이후 12월에 소폭 상승
서비스가 현재 사용자 증가 정체기라고 판단해도 되는 걸까?
아래와 같이 추가적으로 데이터 확인이 필요하다.
1. 월별 신규유저의 접속이 늘어난 건지, 기존유저의 접속이 늘어난 건지?
2. 8-10월까지 유저증가를 위한 프로모션을 진행한 게 있는지? 11월부터 중단한 건지?
구매율을 함께 확인해 보면,

유저가 급증한 10월에도 구매율의 유지가 되고 있는데,
11월에는 10월과 비슷한 수준의 유저수이지만 구매율이 3%p 감소했다.
이런 경우는 10월과 11월의 차이가 무엇인지 상세 분석이 필요하다.
단순 접속유저만 늘어난 건지? 장바구니 유저가 결제단계 이전에 이탈이 많아서인지?
→ Funnel 분석(이탈 구간 분석) 진행
② 일별 사용자 현황

특정 구간의 사용량 증가 원인 파악:
- 8/15 광복절
- 9월 추석연휴
- 10/3,9 개천절, 한글날
- 12/25 크리스마스
공휴일에 사용자가 일시적으로 급격히 증가하는 것을 확인
③ 요일별 사용자 현황

주말이 평일 대비 평균 8% 더 높은 사용자 수 기록
수요일은 평일 중 가장 활발한 사용자 활동
요일 중 토요일의 사용자수가 가장 많고, 수요일, 일요일 순으로 높다.
그러면 토요일, 목요일, 일요일에 프로모션을 해서 사용자를 계속 높이던가,
반대로 사용자가 낮은 요일을 공략해서 사용자를 높여야 하는 걸까?
또는 단편적인 가설로 위의 일별 사용자 현황분석과 더불어
공휴일이 토요일, 수요일에 집중되어 있을 수 있는 경우 인지도 고려해봐야 한다.
여기에 구매자 비율까지 함께 보자

요일별 결제율 변동폭이 11.4%~18.0%로 큰 편
월요일은 낮은 사용자 수 대비 높은 결제율 기록
구매비율까지 확인해 보면, 결국 결제율이 높은 건 일요일, 월요일이다.
그러면 어떤 전략을 제시할 수 있을까?
토요일이 왜 월요일, 일요일보다 결제율이 낮은지 추가 분석해 보고
만약 결제페이지에서 이탈이 많은 거라면, 결제페이지에서 추가 이벤트를 진행할 수 있다.
또는, 가장 개선이 필요한 화요일의 사용자수 저조 원인 파악 분석을 통해 전반적인 지표개선을 진행할 수 있다.
④ 시간대별 사용자 현황


고 활성화 시간: 저녁(18-21시, 29%), 점심(11-14시, 26%)
저 활성화 시간: 새벽(0-6시, 3%), 아침(7-10시, 5%)
배달 어플 도메인 특성상 식사 시간대 사용자가 높은 건 당연할 수도 있다.
이미 사용자 수 1/3 차지하는 저녁 시간대에서 결제율을 높이기 위해 구매 촉진 프로모션을 진행할지,
결제율 변동이 크지만 결제확률이 높은 새벽과 아침시간에 고객 세그먼트 분석으로 타켓층 맞춤 프로모션을 진행할지 고민해 볼 수 있다.
1. 활성화 시간대: 점심과 저녁 시간대에 구매 촉진 프로모션.
2. 저활성 시간대: 새벽과 심야에 맞춤형 할인 제공.
또는, 아래와 같은 추가분석을 통해 새로운 인사이트와 접목시켜 전략을 세울 수 있다.
- 시간대별 행동 패턴 분석
- 연령 및 성별 기준 행동 패턴 분석
윈도우 함수 집계 쿼리
윈도우 함수는 현재 행과 관련된 테이블 행들에 대해 계산하며, 사용자별 이벤트 순위 매기기나 누적 합계 계산 등에 활용할 수 있다.
위 쿼리의 결과값을 가지고 스프레드시트에서 처리를 해도 되고,
아래 쿼리처럼 윈도우 함수를 통해 집계 결과만 출력하여 데이터를 확인할 수도 있다.
-- base 생략
WITH count_users AS (
SELECT
FORMAT_DATE('%Y-%m', event_date) as year_month,
COUNT(DISTINCT user_id) as users,
COUNT(DISTINCT CASE WHEN event_name = 'screen_view' THEN user_id END) as view_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_cart' THEN user_id END) as cart_users,
COUNT(DISTINCT CASE WHEN event_name = 'click_payment' THEN user_id END) as payment_users
FROM base
GROUP BY year_month
),
window_analysis AS (
SELECT
year_month,
users,
cart_users,
payment_users,
ROUND(cart_users * 100.0 / NULLIF(view_users, 0), 2) as view_to_cart_rate,
ROUND(payment_users * 100.0 / NULLIF(cart_users, 0), 2) as cart_to_payment_rate,
-- 전월 대비 증감
LAG(users) OVER (ORDER BY year_month) as prev_month_users,
LAG(cart_users) OVER (ORDER BY year_month) as prev_month_cart_users,
LAG(payment_users) OVER (ORDER BY year_month) as prev_month_payment_users,
-- 증감률 계산
ROUND((users - LAG(users) OVER (ORDER BY year_month)) * 100.0 /
NULLIF(LAG(users) OVER (ORDER BY year_month), 0), 2) as user_growth_rate,
-- 누적 사용자
SUM(users) OVER (ORDER BY year_month) as cumulative_users,
-- 전체 기간 중 비율
ROUND(users * 100.0 / SUM(users) OVER (), 2) as percentage_of_total
FROM count_users
)
SELECT
year_month,
view_to_cart_rate,
cart_to_payment_rate,
user_growth_rate as month_growth_rate,
percentage_of_total as total_share
FROM window_analysis
ORDER BY year_month
쿼리 결과

마무리
현업에서는 위와 같은 사용자 수 같은 단일 지표만 가지고 현황을 파악하거나, 이를 기반으로 액션 아이템의 의사결정을 하는 일은 거의 없다. 단편적인 데이터만으로는 전체 상황을 파악할 수 없기 때문이다. 데이터는 불완전할 수 있고, 함정이 숨어 있을 수 있다.
예를 들어, 위 분석도 사실 전체기간의 사용자 수로만 판단하면 안 되고, 급증한 월의 요일, 시간대별 데이터가 전체 데이터를 왜곡할 수 있어 세부 분석이 필요하다. 이렇듯 분석은 데이터를 다각도로 보고, 최선의 선택을 위한 데이터를 찾아가는 반복과정이다. 그래서 데이터 분석은 다양한 방법론과 고려사항을 파악해 진행해야 한다.
또한 위 분석자료 기반으로는 대부분의 의문을 남기고 결정은 뚜렷하게 할 수 없는데, 그건 테스트 데이터셋으로만 보고 판단할 수 없는 부분이기 때문이다. 데이터 한계보다는 현재 회사가 어떤 프로모션을 진행하고, 어떤 방향성으로 전략을 진행하고 있는지와 같은 비즈니스 상황을 고려해야 하기 때문이다. 하나의 데이터만 맹목적으로 신뢰하고 판단할 수 없다.
결국, 이 글에서 말하고 싶은 것은 데이터 분석 결과가 나왔을 때, 어떤 관점과 생각 흐름으로 데이터를 뜯어봐야 하는지이다.
레퍼런스
인프런 카일스쿨님의 'BigQuery(SQL) 활용 편'의 데이터셋 및 강의내용을 참고하였습니다.
'데이터분석 > 데이터 리터러시' 카테고리의 다른 글
| 데이터분석가의 데이터 수집 단계 회고 (feat.데이터분석 하러 왔는데, 데이터를 만들라고요?) (0) | 2024.12.22 |
|---|---|
| Funnel 분석 - 이탈 구간 데이터분석 (0) | 2024.11.10 |
| KPI (핵심성과지표) 설정 및 관리 (0) | 2024.10.27 |